LLMs for Structural Engineers: How AI Language Models Actually Work
 clearspan
clearspan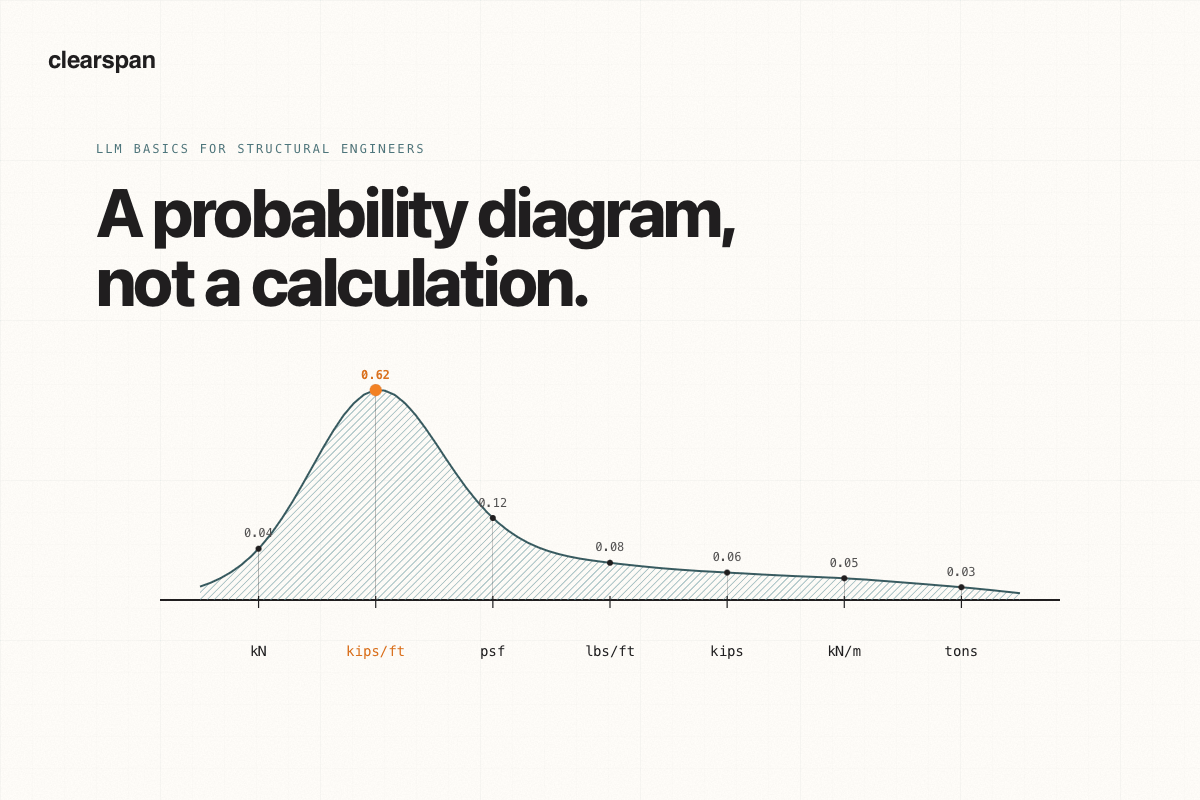
If you've watched the wave of "AI" features roll into design tools, code-checking software, and project management platforms over the past couple of years, you've almost certainly run into the term LLM (large language model). ChatGPT, Claude, and the assistants now embedded in everyday software all sit on top of one.
Most explanations are written for software developers or for a general audience. This one is written for you: a practicing structural engineer who wants to understand what these systems are, how they're built, and, critically, where they should and shouldn't be trusted on real work.
What an LLM Actually Is
Strip away the marketing and an LLM is a prediction engine for text. Given a sequence of words, it predicts the most plausible next chunk of text, then repeats. That's it. The "intelligence" is an emergent property of doing that prediction extraordinarily well across an enormous range of material.
Think about how you developed engineering intuition. After running hundreds of beam checks, you can glance at a beam span and estimate the member size before you touch a calculator. You're not deriving it from first principles in that moment; you're pattern-matching against thousands of prior examples burned into your memory.
An LLM does something somewhat similar, but with language. It has "seen" so much text that it has internalized the statistical patterns of how ideas, sentences, and explanations fit together. When you ask it a question, it isn't looking up an answer in a database. It's generating a response one token at a time based on those learned patterns.
An LLM produces what is plausible, not what is verified. Like an engineer's gut estimate, it's often right and genuinely useful, but it is not a calculation, and it carries no inherent guarantee of correctness.
How LLMs Are Trained
A model goes through distinct phases before it's useful, and each one maps cleanly onto a stage of professional development.
Phase 1: Pretraining: Building Raw Intuition
In pretraining, the model reads a massive corpus of text: books, articles, code, technical documentation, and a large slice of the public internet. Its only job during this phase is to predict the next token over and over, billions of times, adjusting its internal parameters whenever it guesses wrong.
This is the equivalent of time spent in university courses or in your early career. You absorb an enormous volume of material (codes, textbooks, project drawings, mentor feedback) without yet being asked to deliver the most polished, accountable work. You're building the substrate.
The result of pretraining is a model with broad, general competence but no particular manners. It can complete text, but it doesn't yet reliably answer questions or follow instructions the way you'd want.
Phase 2: Fine-Tuning: Learning the Discipline
Supervised fine-tuning narrows that raw capability toward useful behavior. The model is trained on curated examples of good question-and-answer pairs, instructions and ideal responses, and the like. This is where it learns to behave like an assistant rather than an autocomplete engine.
Think of this as specializing. A structural engineer and a geotechnical engineer share a common foundation, but each spends years tuning toward the conventions, vocabulary, and expected outputs of their discipline. Fine-tuning is that same tuning step, shaping general ability into a specific, reliable form.
Phase 3: Reinforcement Learning from Feedback: The QA Review
The final common phase is reinforcement learning from human feedback (RLHF). Here, humans rank the model's responses, and the model is nudged toward the answers people judged better: clearer, more honest, more helpful, less likely to fabricate.
This is the closest analog to a senior engineer's red-line review. The junior produces work, the reviewer marks up what's wrong, what's unclear, and what's unacceptable. Over many cycles the junior's instincts shift toward what passes review. RLHF is that feedback loop applied at scale, and it's a large part of why modern models feel cooperative and reasonably careful rather than erratic.
RLHF improves behavior and judgment, not factual ground truth. A model can be trained to sound calibrated and cautious while still being confidently wrong about a specific load combination. The review process polishes delivery far more than it guarantees accuracy.
How Inference Works (Using the Model)
Once trained, using a model is called inference. A few concepts are worth knowing because they directly affect reliability on technical work.
Tokens. Models don't read words; they read tokens (roughly word fragments). "Cantilever" might be one token; a full code reference might be several. Both your input and the model's output are measured in tokens, which is also how most AI tools price usage.
The context window. This is the model's short-term working memory: the total amount of text (your prompt plus its prior responses plus any documents you've pasted) it can consider at once. Exceed it, and the earliest material falls out of view. In practice, if you paste a 40-page report and then ask a question, the model may no longer "see" the opening sections. It behaves like a brilliant engineer with no long-term memory of the meeting, sharp within the conversation but blank about anything that scrolled off the page.
Temperature. A setting that controls randomness. Low temperature yields consistent, conservative output; higher temperature yields more varied, creative output. For anything resembling calculation or code interpretation, you want low.
No live knowledge by default. A base model only knows what was in its training data up to a cutoff date. It does not know the current code edition, your local amendments, or yesterday's RFI response unless those are explicitly provided in the context window or fetched by a connected tool.
Where LLMs Help, and Where the Load Path Breaks
For structural engineering specifically, the strengths and failure modes are fairly predictable.
LLMs are genuinely useful for:
- Drafting and editing (proposals, RFI responses, spec narratives, client emails)
- Explaining code provisions or summarizing a long document into the points that matter
- Generating boilerplate calculation write-ups and methodology sections
- Translating between formats, turning rough notes into a clean scope, for instance
They fail in ways that matter on stamped work:
- Hallucination. A model can invent a plausible-sounding code section, citation, or formula that simply doesn't exist. It states it with the same confidence as a correct answer.
- Arithmetic and unit handling. General-purpose LLMs are unreliable narrators of their own math. They can describe the right method and then botch the numbers, or silently mix units.
- No accountability. A model has no license, no liability, and no stake in the outcome. It cannot stamp anything, and it cannot be the responsible engineer of record.
An LLM is like an extraordinarily well-read, fast, tireless junior engineer who is also occasionally and confidently wrong, and who will never sign the drawings. You delegate the right tasks to that person and you check the work, especially anything load-bearing.
What This Means for Structural Practice
A more useful question than "will AI replace structural engineers?" is which parts of your workflow suit a fast pattern-matcher, and which parts demand verified analysis and professional judgment.
The narrative work (documentation, explanation, communication, drafting) is increasingly fair game for AI assistance, with review. The engineering judgement itself is best left with the licensed professional. Well-designed tools reinforce that boundary rather than blur it, using AI to remove the busywork around a calculation while keeping the calculation itself transparent, checkable, and owned by an engineer.
Clearspan is built around that boundary. We create tools for AI to use that separate the math and report generation from the LLM. This means the LLM can operate to its strengths of pattern matching. We tell it what tools are for, and it will use them. The engineer can then open the tool output for easy review and editing, but the model has done most of the busy work. Clearspan is tooling for real engineers, not a substitute for them, and the goal is letting engineers turn around stamped work faster without compromising the judgment their license represents.
If you're a structural engineer curious about where AI fits into your practice, or a firm interested in faster turnaround on residential calculation packages without giving up control of the work, learn how Clearspan works.
Clearspan offers tested AI tools that make your work more efficient, improve client service, and grow your web presence.